

When Statistical Pattern Matching Fails: A Dating App Lesson in Information Theory
Why and How Pattern Matching Works for Gmail Smart Compose—but Fails for Human Matching


I created a dating app recommendation tool for my own research purposes.
I used data such as age, location, interests and past matches. I then posed the following question:
“What person would be the best match for Alex?”
The results were that there was an excellent match with everyone.
Nest: 92% match
Siri: 89% match
Sonos: 91% match
Even with someone else in another country with a different language - 87% match.
Here's what my model saw

People love coffee; therefore, they are all alike.
The model detected a pattern but it was not a significant one; it was merely... correlation.
What Does Statistical Pattern Matching Mean?
Statistical pattern matching is, in fact, just as it sounds — to find patterns in data statistically.
However, the problem here is patterns ≠ meaning.
My model was functioning exactly according to parameters I included within it. Specifically, it measured three characteristics of individuals:
Age Group: ±5 years
Geographical Proximity: Same city
Shared Interests: Overlapping with Hobbies
Together, these characteristics created a situation where almost everyone in the data set shared either of these characteristics with others who also shared them with me and as a result the model had no means by which to make different classifications amongst those having the exact same characteristics either.

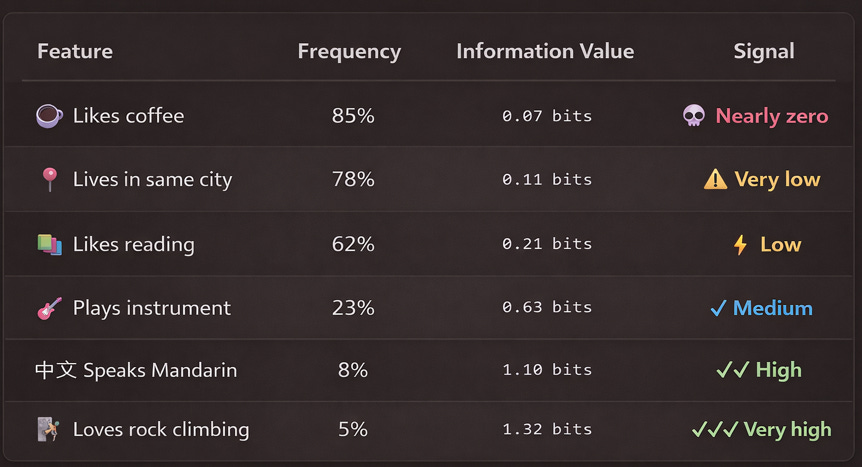
If 85% of people like coffee:
Knowing someone likes coffee tells you they’re... like 85% of people. You learned almost nothing.
If 5% of people rock climb:
Knowing someone rock climbs immediately places them in a specific 5% subset. You learned a LOT.
The formula for information value:
Information Value = -log(frequency)
This is the foundation of Information Theory. The less frequently something occurs, the more information it carries when it does occur.
This is why my original model failed.
I treated coffee (0.07 bits) and rock climbing (1.32 bits) as equally important. The model saw 19x more signal in noise than in actual meaningful features
Wait—Doesn’t Gmail Do This Successfully?
You might be thinking: “But Gmail’s Smart Compose uses statistical pattern matching, and it works great!”
You’re right. And understanding why it works reveals exactly when pattern matching succeeds—and when it fails catastrophically.
The difference between Smart Compose and my dating app?
Constraint. Smart Compose works in an extremely narrow, repetitive domain. My dating app tried to match humans.
How Smart Compose Actually Learned
Imagine training data that looks like this:
Email 1: “Hi, hope you’re having a great day. I wanted to...”
Email 2: “Hello, hope you’re doing well. Quick question about...”
Email 3: “Hi there, hope you’re good. Can we schedule a...”
Email 4: “Hey, hope you’re having a good one. Just checking in...”
The system doesn’t read these as sentences with meaning. It reads them as sequences of tokens (words or subwords).
After seeing millions of examples, it learns:
When it sees “Hope you’re” → the next token is usually something positive: “having,” “doing,” “well”
When it sees “having” after “Hope you’re” → the next token is usually “a” (not “being” or “some”)
When it sees “Hope you’re having a” → the next token is usually a positive noun: “great,” “good,” “wonderful”
These patterns emerge statistically from the data.
Not because anyone programmed them. Not because the system understands hope or days. Just from counting: in how many emails did this sequence appear, and what usually came next?

Why It’s Powerful in Narrow Domains
In email, the repetition is extreme. People use the same greetings, closings, and structures over and over:
“Thanks for”
“Looking forward to”
“Best regards”
“Let me know if”
These appear in nearly identical sequences tens of thousands of times. Statistical pattern matching thrives on this repetition.
But take the same system out of email and it falls apart. Ask it to predict the next word in a poem, or a legal document, or a technical specification. Different domain, different patterns, different repetition structure.
The model learned email patterns. When you feed it something else, it’s like asking a weather model trained on tropical data to predict arctic weather.
What It Can’t Do
Statistical pattern matching can’t understand causation. It can’t say “the reason people write ‘thanks for’ is because they’re expressing gratitude.” It just knows: these tokens tend to follow those tokens.
It can’t infer intent from context. If you write “Hope you’re having a great day—just kidding, this is terrible,” the system still predicts positive-word completions, because it learned the pattern from successful emails, not from the occasional ironic ones.
It can’t reason about novelty. If you start a sentence no one in the training data ever started that way, the system has no learned pattern to fall back on. It makes a guess based on the closest pattern it knows, and often gets it wrong.
But here’s why this matters:
For narrow tasks like email completion, this is exactly what you need. You don’t need understanding. You need accuracy on repetitive patterns. And that’s where statistical pattern matching excels.
Constrained domain + Repetitive patterns + Scale = Reliability

Pattern Matching vs. Pattern Reasoning: The Critical Difference
Pattern Matching: “When I see X, Y usually follows.”
Pattern Reasoning: “When I see X, I need to figure out why Y follows, and whether it will follow in this specific case.”
Pattern Matching: The Email Example
Smart Compose sees:
“Hope you’re having” → 89% of the time followed by “a great”
“Hope you’re having a” → 92% of the time followed by “great day”
Decision: Predict “great day”
Reasoning required: Zero. The pattern is the answer.
Pattern Reasoning: The Dating Example
My algorithm sees:
Alex likes coffee ☕
Siri likes coffee ☕
Pattern detected: 85% of users like coffee
Pattern matching says: High match! Both like coffee.
Pattern reasoning asks:
Why does this pattern exist? (Because coffee is popular everywhere)
Does this pattern mean anything? (No, it’s just common preference)
Should this influence the decision? (No, find a rarer, more meaningful pattern)

The Problem with Modern AI
Most modern AI systems including large language models are fundamentally pattern matchers, not pattern reasoners.
They’ve gotten incredibly good at:
Finding patterns in massive datasets
Identifying correlations
Predicting what usually comes next
But they struggle with:
Understanding why a pattern exists
Knowing when a pattern is spurious
Reasoning about whether a pattern applies in a novel situation
My dating app needed pattern reasoning. I gave it pattern matching. That's why everyone liked coffee, and everyone was a "perfect match."
How I Fixed It: TF-IDF for People
The solution came from an unexpected place: text analysis.
In natural language processing, there’s a technique called TF-IDF (Term Frequency-Inverse Document Frequency).
It answers the question: How important is this word in this document?
Breaking Down TF-IDF: The Two Parts
TF-IDF has two components, and understanding each one is key to understanding why it works


The logarithm is important here. It prevents extremely rare words from dominating, while still giving them high weight.
Putting It Together: TF × IDF
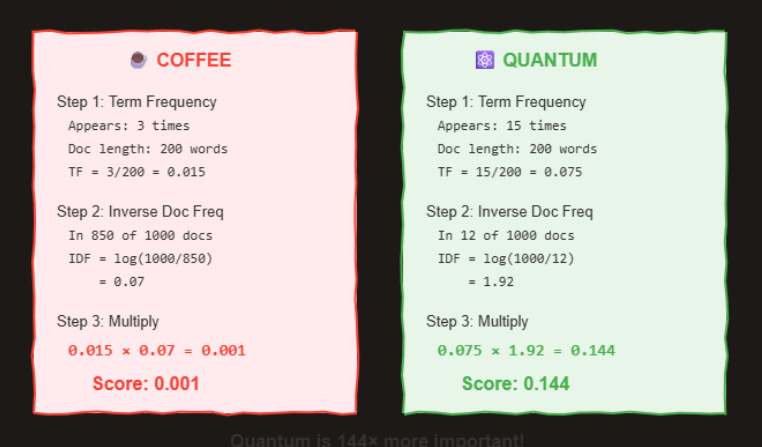
Real calculation showing why “quantum” scores higher than “coffee”
Let’s see a complete example:

“Quantum” is 144× more important than “coffee” to this document.
Why This Formula Is Brilliant
TF-IDF elegantly combines two insights:
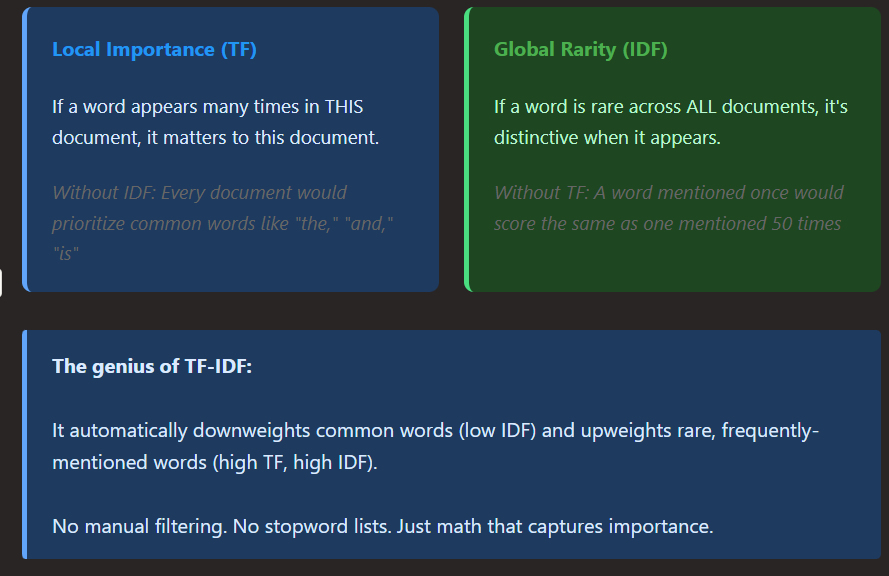
The formula translates perfectly:
Feature Weight for User:
Weight = (Feature present? 1 : 0) × log(Total users / Users with feature)
Simplified: If user has feature, weight = log(Total / Count), else 0
What I Learned
My dating app doesn’t match everyone with everyone anymore.
Not because I added more features.
Not because I trained a bigger model.
But because I stopped asking “what patterns exist?”
and started asking “which patterns matter?”
Statistical pattern matching will always find correlations.
That’s what it’s designed to do.
But correlation alone is cheap.
It’s everywhere.
And without context, it’s often meaningless.
Pattern reasoning is different.
It asks why a pattern exists, whether it’s informative, and whether it should influence a decision at all.
That distinction matters far beyond dating apps.
It’s the difference between autocomplete and understanding.
Between ranking and reasoning.
Between systems that look intelligent—and systems we can actually trust.
Sometimes the best model isn’t the one that finds the most patterns.
It’s the one that knows which patterns to ignore.